
Let’s practice some Web Hacking. For this purpose, there is a good resource developed by Google. It’s a Website called Google Gruyere; it is a Hacking Lab, and as per it’s name, it is riddled with vulnerabilities. Link : https://google-gruyere.appspot.com/
This website mimicks the principles of a very basic social network, where you can create a user profile (name, photo, pinned message and website…), manage it, and post some short messages (snippets in this case), so it really makes sense as a study material
The Lab shows how web application vulnerabilities can be exploited and how to defend against these attacks. Among other Challenges, we will practice cross-site scripting (XSS), cross-site request forgery (XSRF),…and also get an opportunity to assess the impacts of such vulnerabilities ( denial-of-service, information disclosure, remote code execution…)
Some of these Challenges can be solved by using black box techniques, other Challenges will require to look at the Gruyere source code (that’s why Google provides both client side and server side code along with the Lab). The code is written in Python. Reading through the code will help build a good understanding how the vulnerabilities work. The code relies on Templates – Gruyere Template Language or GTL – , and in this respect, look similar to Django (https://www.djangoproject.com/start/overview/)
Google provides all the solutions on the Gruyere site, so I’m not going to provide new solutions but rather walk through the proposed solutions
Introduction to Gruyere
The Lab looks like this when you launch it for the first time (it will create an incremental session number, specific to you)
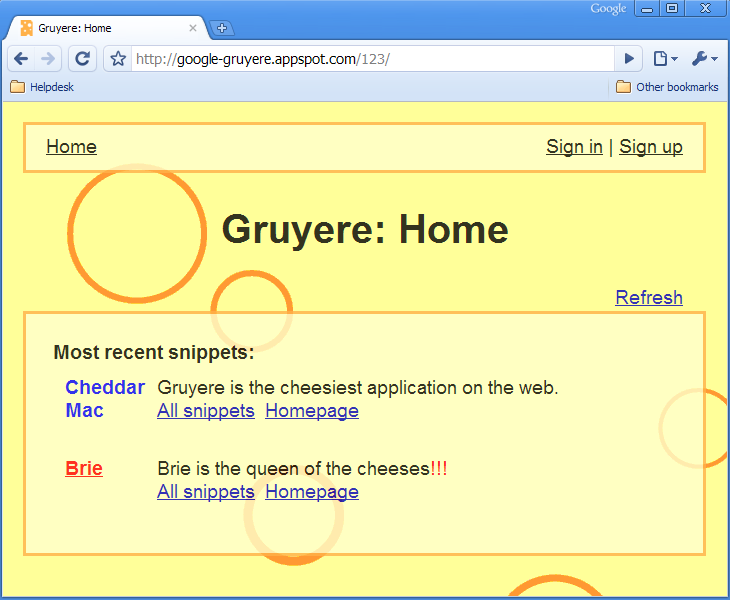
As a warm-up, we are requested to perform a few basic tasks, to gain a first understanding of the user interface :
- View another user’s snippets by following the “All snippets” link on the main page. Also check out what they have their Homepage set to
- Sign up for an account for yourself to use when hacking
- Fill in your account’s profile, including a private snippet and an icon that will be displayed by your name
- Create a snippet (via “New Snippet”) containing your favorite joke
- Upload a file (via “Upload”) to your account
This is what my login page now looks like :

About snippets : some of you may not know where this comes from. It is the usual word used by Google to highlight a summary text in the Google search engine result. In our context, a snippet refers to a small bit of text added as a tag, after a user name
Before going through the Challenges, let’s have a first look into the code (I’m using the code editor “Sublime Text”)
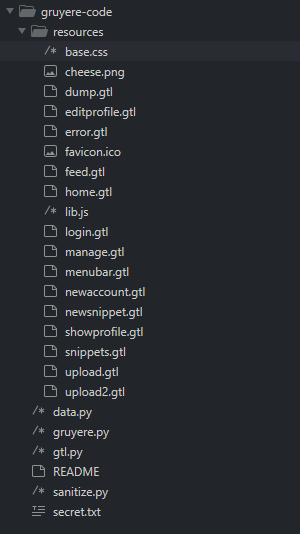
Here is a short explanation about the Gruyere modules (we will come back to it with deeper analysis during the Challenges) :
data.py stores the default data in the database. There is an administrator account and three default users
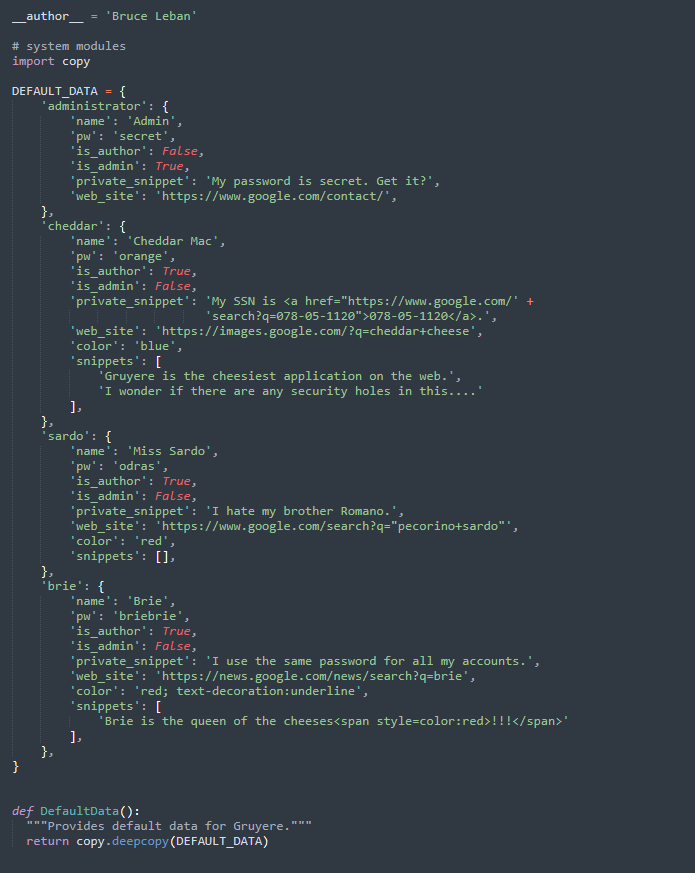
gruyere.py is the main Gruyere web server
The code enables the setup of a local server with the necessary functionalities (creation of a working directory, installation of a database, cookie management, URL/HTML responses, management of user profile, data/file upload,…)
Here are important text comments included in the code, it helps understand the server logic and limitations
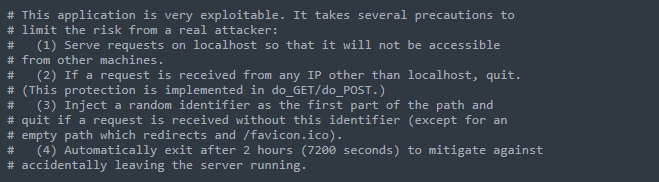
gtl.py is the Gruyere Template Language
Gruyere Template Language (GTL) is a new template language, and as its siblings such as Django, it helps create web pages more efficiently. Documentation for GTL can be found directly in gruyere/gtl.py
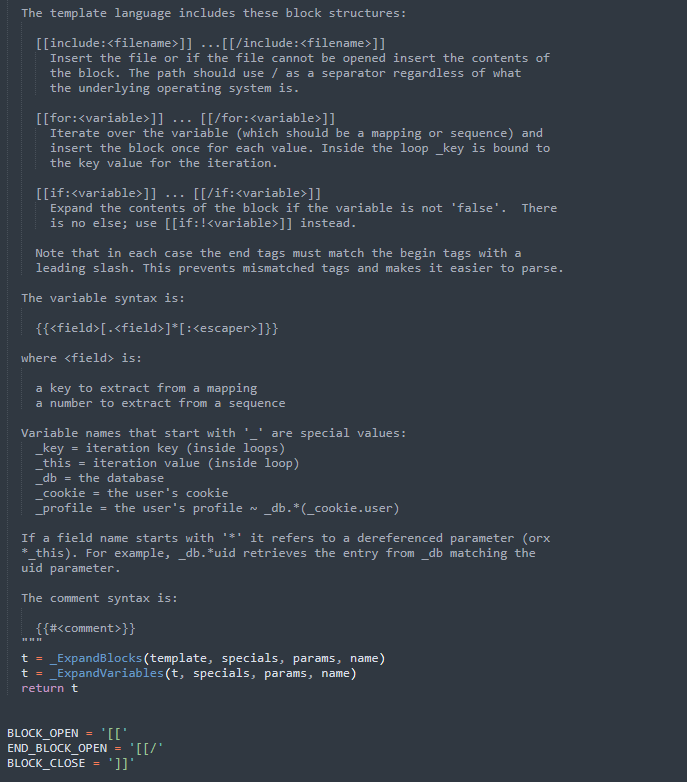
Most of the Gruyere resources are written using GTL
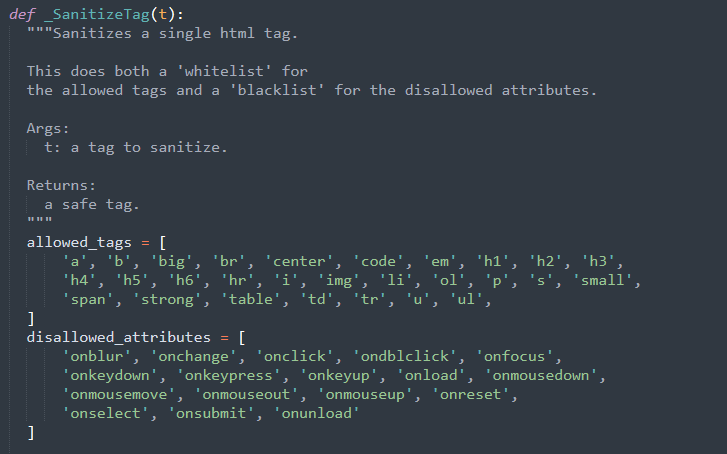
sanitize.py is the Gruyere module used for sanitizing HTML, to protect the application from security holes
HTML sanitization is the process of examining an HTML document and producing a new one that preserves only whatever tags are designated “safe” and desired. HTML sanitization can be used to protect against attacks such as cross-site scripting (XSS) by sanitizing any HTML code submitted by a user. For example, tags such as <script> are usually removed during the sanitizing process. The process is usually based upon a white list of allowed tags, and a black list of disallowed tags
In our case, here are the allowed/disallowed tags
resources directory holds all CSS code, images, template files (it will provide important functionalities such as account creation, login process, user profile, snippets, file upload), and a Javascript library (for snippets user interaction and refresh)
Data Sanitization and Escaping
We should always be very carefull with user inputs on our websites. Some users will try to “inject code” in our website, using different tricks (as we will see below in the following Challenges)
The root cause of code injection vulnerabilities is the mixing of code and data which is then handed to a browser. Injection is possible when the data is treated as code
Data sanitization and Escaping is a mitigation for code injection vulnerabilities
Sanitization involves removing characters entirely in order to make the value “safe”. Sanitization is difficult to do correctly, that’s why most sanitization implementations have seen a number of bypasses
The term “Escaping” originates from situations where text is being interpreted in some mode and we want to “escape” from that mode into a different mode
For example, you want to tell your terminal to switch from interpreting a sequence of code to text
One common situation is when a developer needs to tell a browser to not interpret a value as code but as text
Please keep in mind these concepts as they will be important for the Challenges
If you want to go deeper on these topics before starting the Challenges, you could check this OWASP video about “killing injection vulnerabilities“
Cross-Site Scripting (XSS)
Cross-site scripting (XSS) is a vulnerability that permits an attacker to inject code (typically HTML or JavaScript) into contents of a website not under the attacker’s control. When a victim views such a page, the injected code executes in the victim’s browser. Thus, the attacker can steal victim’s private information associated with the website in question
File Upload XSS
This attack is well documented by the OWASP Foundation : https://bit.ly/3xVUjqE
We can create the following file, including a warning message “Forensicxs hacked you”, and a script – Javascript – that will pop-up the content of the session cookie
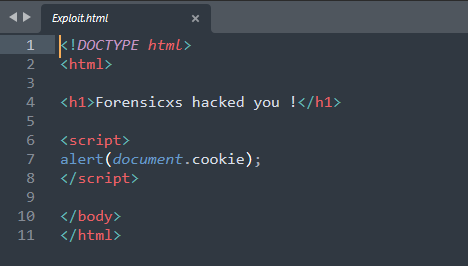
Here below a bit more information about cookies and the potential use of document.cookie

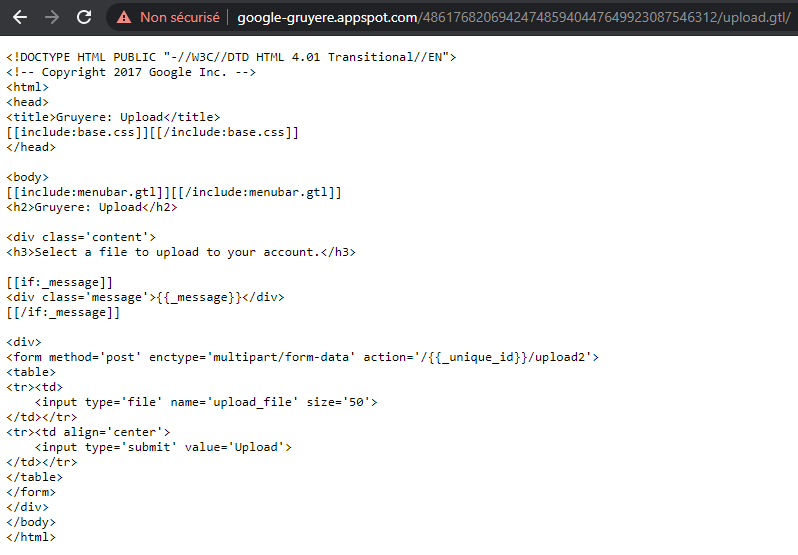
Let’s upload our HTML file into Gruyere. Once the upload is completed, we are provided with an https link to access our file directly from the browser

Let’s follow this link in our browser. We get the alert(document.cookie) pop-up window displayed. It provides the content of our session cookie

When we click OK, we land on our HTML message “Forensicxs hacked you”. In developer mode, we can confirm the cookie value
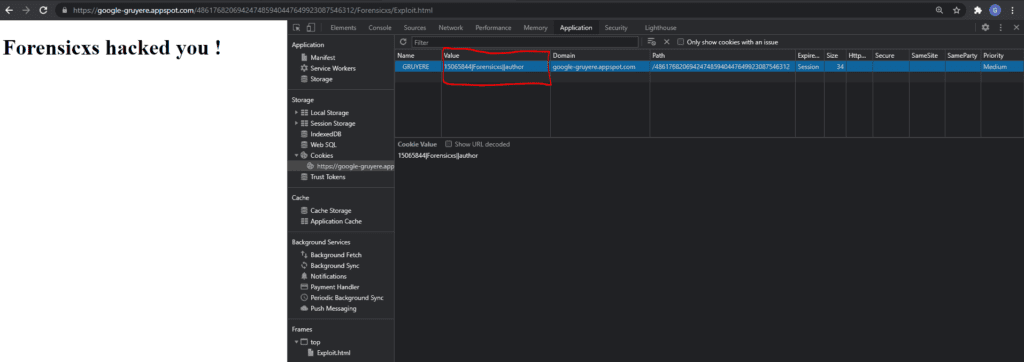
The cookie content is consistent with the server side code
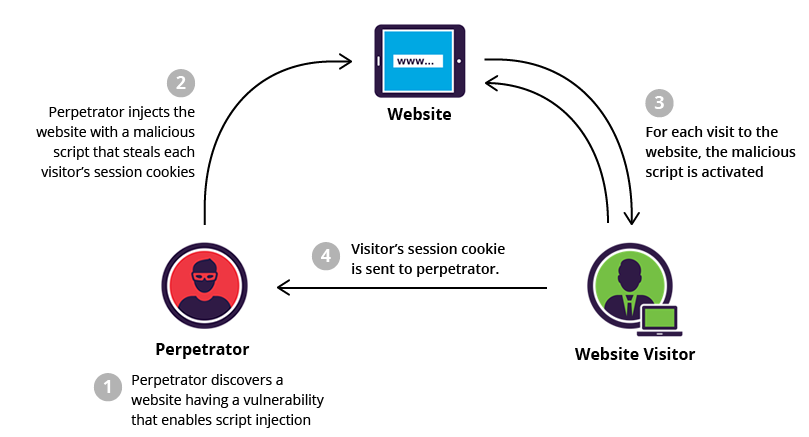
Our script is very basic, but we could write a more sophisticated one, that would be able to steal user informations contained in the cookie. The next step of the hack is to make the upload link (https://bit.ly/3jYcVl7) available to our victim, and once he clicks on it, this will run the script on his session and steal the data as per the script (with our basic script, we will not be able to retrieve the user data). Since the file we uploaded is on a trusted site, a user will more likely trust the link and click on it. As a summary, the attack looks as follows :
There are many countermeasures detailed by the OWASP : https://bit.ly/3xVUjqE. Here below some important ones :
- host the content on a separate domain so the script won’t have access to any content from your domain. That is, instead of hosting user content on
example.com/usernamewe would host it atusername.usercontent.example.comorusername.example-usercontent.com. (Including something like “usercontent” in the domain name avoids attackers registering usernames that look innocent likewwwwand using them for phishing attacks.) - the application should perform filtering and content checking on any files which are uploaded to the server. Files should be thoroughly scanned and validated before being made available on the server. If in doubt, the file should be discarded
We can see in the Gruyere code that none of these protections are included in the server side
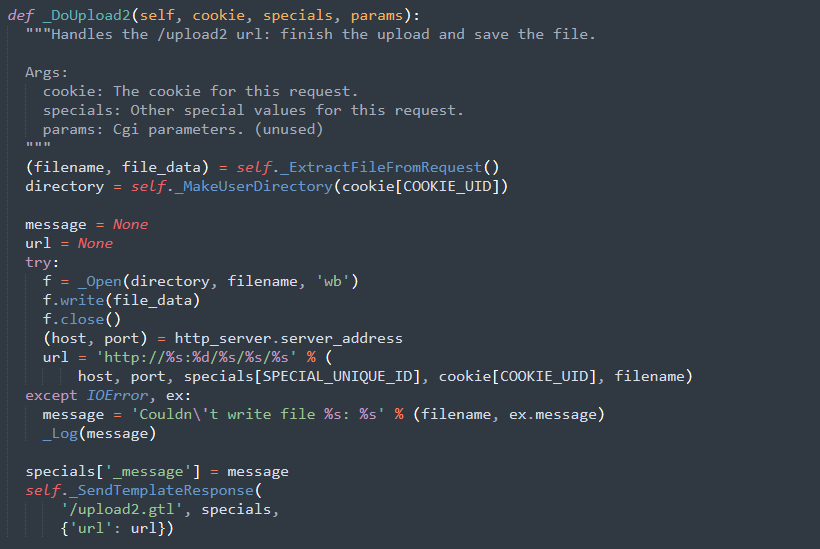
Reflected XSS
This attack is well documented by the OWASP Foundation : https://bit.ly/3CUevwZ
Reflected cross-site scripting arises when an application receives data in an HTTP request and includes that data within the immediate response in an unsafe way. For example :

The questions guide us to type in “invalid” in the adress bar. We get an error message as this adress leads to nothing on Gruyere Website
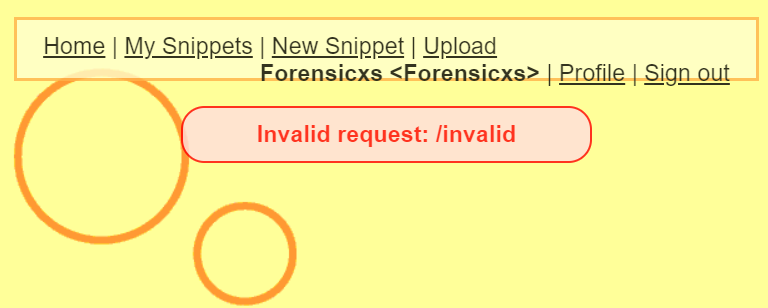
And we can see in the Developer tools that the code has been inserted
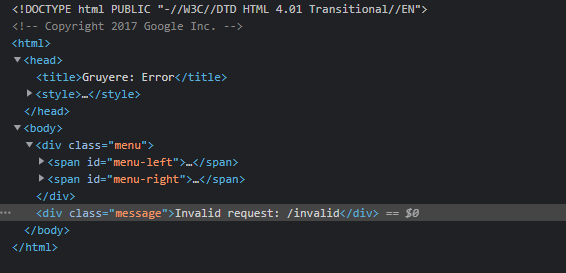
In a reflected XSS, an attacker forces the web-application to return an error search result, or any other response that includes some or all of the input provided by the user as part of the request, without that data being made safe to render in the browser, and without permanently storing the user provided data
The questions provide us tips about potential code to type in. Let’s type again a script such as this one : <script>alert(document.cookie)</script>
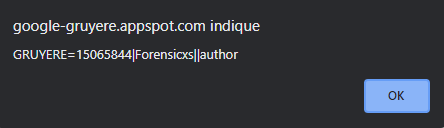
Our session cookie is displayed in the message box, and we can also see the script inserted in the Elements inspector
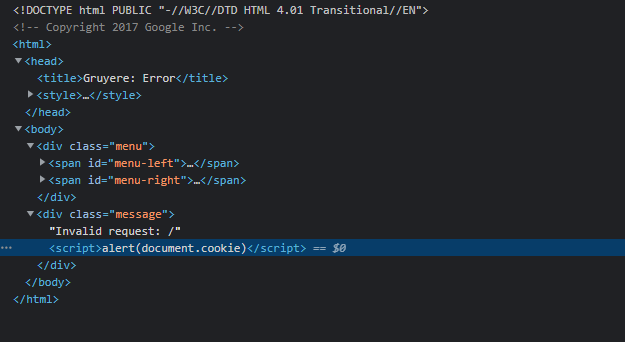
This is the demonstration of the Reflected XSS. We could pass this link to a victim and steal its session informations (but we would need a more complex script to retrieve the victim’s data)
Now, let’s have a look at the flaws in the code. One issue is that Gruyere sends us an error message, but the script is included in the output rendered code (as seen before in the Elements inspector)
As per Google statement in the Challenge, one fix is to escape the user input that is displayed in error messages. Error messages are displayed using error.gtl, but are not escaped in the template. The part of the template that renders the message is {{message}} and it’s missing the modifier that tells it to escape user input. Add the :text modifier to escape the user input. This is called manual escaping
<div class="message">{{_message:text}}</div>
I try to fix this issue by downloading the Gruyere code, modifying it and running it locally
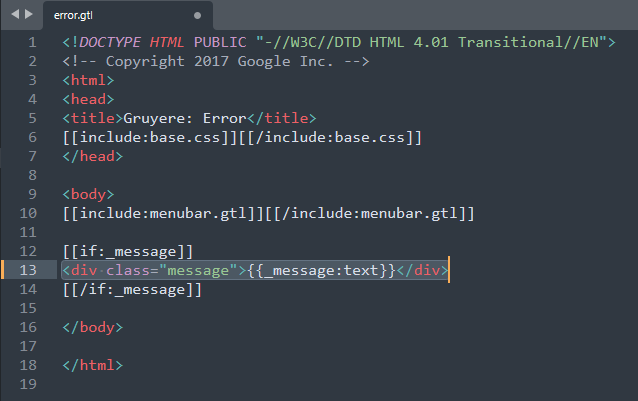

We can see that the script is escaped to text and the script is not executed

The simplest and best means to protect an application and their users from XSS bugs is to use a web template system or web application development framework that auto-escapes output and is context-aware
“Auto-escaping” refers to the ability of a template system or web development framework to automatically escape user input in order to prevent any scripts embedded in the input from executing. If you wanted to prevent XSS without auto-escaping, you would have to manually escape input; this means writing your own custom code (or call an escape function) everywhere your application includes user-controlled data. In most cases, manually escaping input is not recommended
“Context-aware” refers to the ability to apply different forms of escaping based on the appropriate context. Because CSS, HTML, URLs, and JavaScript all use different syntax, different forms of escaping are required for each context
Here in the link an article about how the template language Django handles autoescaping and various other XSS protections : https://bit.ly/3sGT6CU. There is no such autoescaping in the GTL language
Stored XSS
This attack is well documented by the OWASP Foundation : https://bit.ly/3CUevwZ
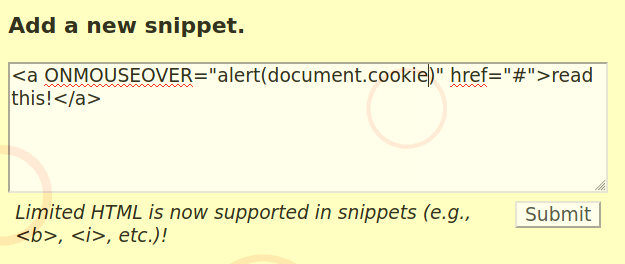
As induced by the questions, we can input the following script in the “New Snippet” form

After clicking Submit, we can hover our mouse on the “read this” link, and again, we see a pop-up window with our session cookie
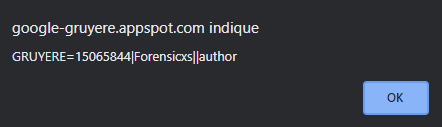
We can see that our script has been embedded in the code
Any user who would hover its mouse on my snippet would face a risk (but actually stealing any user data would require a more complex script). So, what is wrong with the code ? We do have a Sanitizer, but obviously it’s too weak to catch this threat
The call to the Sanitizer is done in this piece of code, inside the Template language GTL
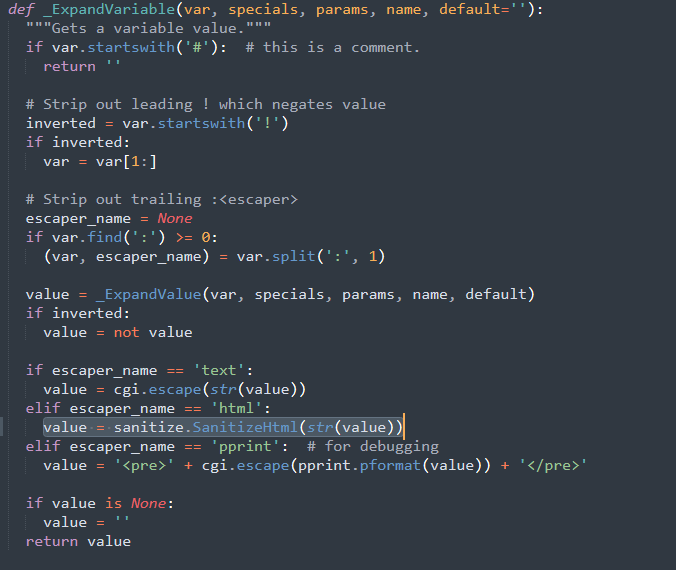
Let’s have a deeper look at sanitize.py
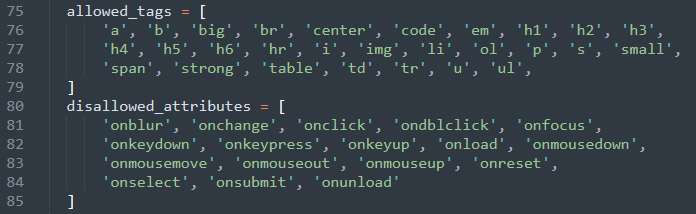
The attribute “onmouseover” is not in the disallowed attributes. That’s an obvious flaw. Let’s add this attribute in the code and let’s test again
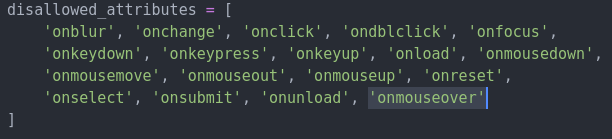
Now, the script is not executed, it’s blocked by this additional disallowed attribute. But, if write the “ONMOUSEOVER” in capital letters, the script is executed again
So we can see how the Sanitizer is sensitive to upper/lower cases and probably other parameters. Developping our own Sanitizer is surely not a robust method
As per Google, the right approach to HTML sanitization is to :
- Parse the input into an intermediate DOM structure, then rebuild the body as well-formed output
- Use strict whitelists for allowed tags and attributes
- Apply strict sanitization of URL and CSS attributes if they are permitted
This is done using a proven HTML sanitizer, such as this one : https://bit.ly/3sx15SW
Stored XSS via HTML Attribute
Let’s start with a usefull reminder about HTML attributes : https://bit.ly/2W5b9a5
Here is an example based upon the style attribute, allowing to add style to an element, such as color

Now, let’s start the Challenge. My profile color is green

We are totally guided here and just need to type the following script in the profile box

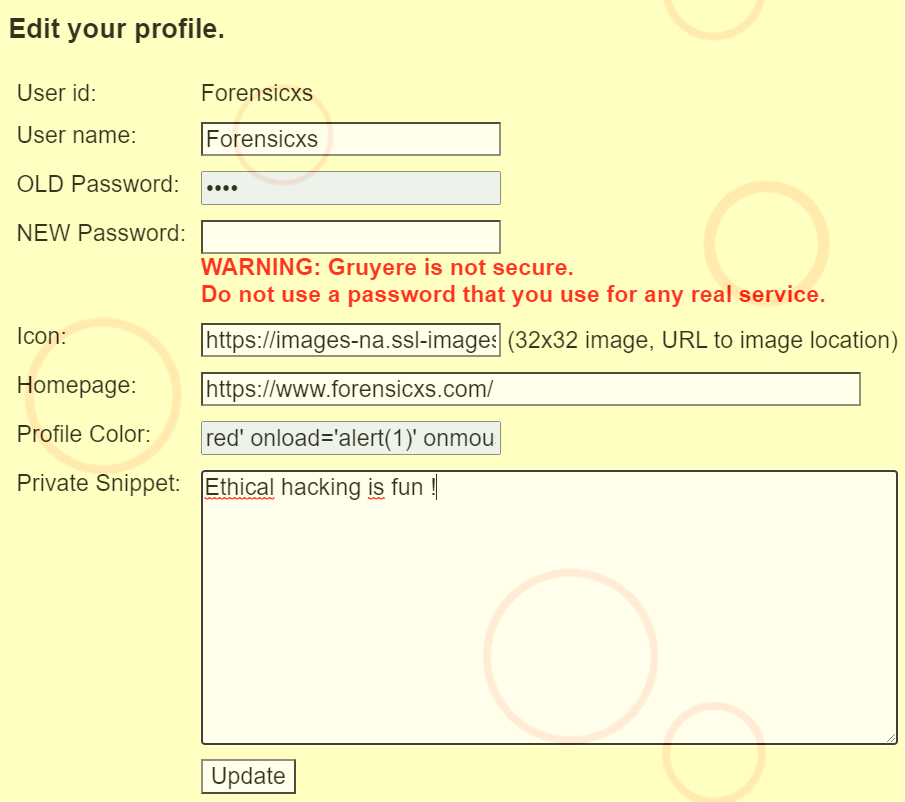
The script is launched each time the mouse hovers over the profile name
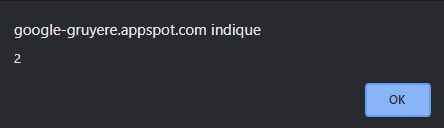
Now, let’s check in the code where this flaw is occuring. There are two noticeable code sections where colours are managed. The first one is in “home.gtl”. We can see that the color parameter is escaped as follows : {{color:text}}
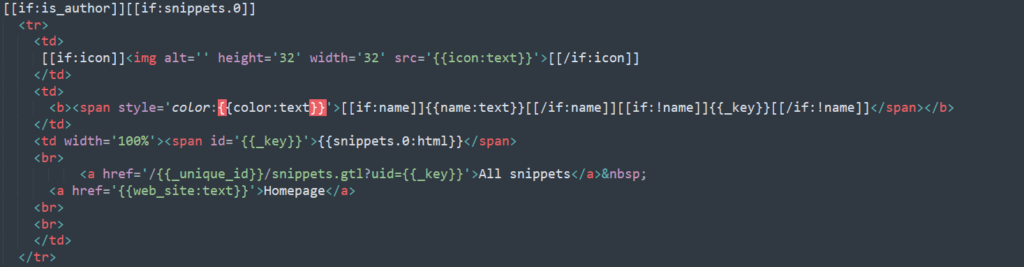
The second one is in “editprofile.gtl”. The color parameter is also escaped as follows :{{_profile.color:text}}

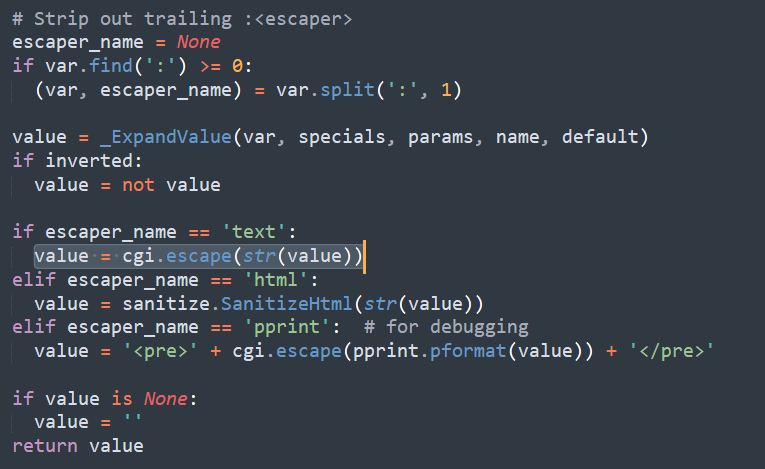
So, how come the script is executed ? The bug is in this code section of glt.py
What is CGI ? Common Gateway Interface (CGI) is an interface specification that enables web servers to execute an external program, typically to process user requests
A typical use case occurs when a Web user submits a Web form on a web page that uses CGI. The form’s data is sent to the Web server within an HTTP request with a URL denoting a CGI script. The Web server then launches the CGI script in a new computer process, passing the form data to it. The output of the CGI script, usually in the form of HTML, is returned by the script to the Web server, and the server relays it back to the browser as its response to the browser’s request
CGI is a rather old technology. It requires some coding effort for complex websites. Nowadays, the Frameworks such a Django (Python) will manage the link between the Front-End and Back-End more efficiently
Now, back to the code. During a user input, cgi.escape is designed to escape the user HTML attribute, considering a double quote “, as per this example

But in our script, we have just put single quotes ‘
That’s why the script is slipping through the cgi.escape function and is executed
To be noted : cgi.escape will never escape single quotes
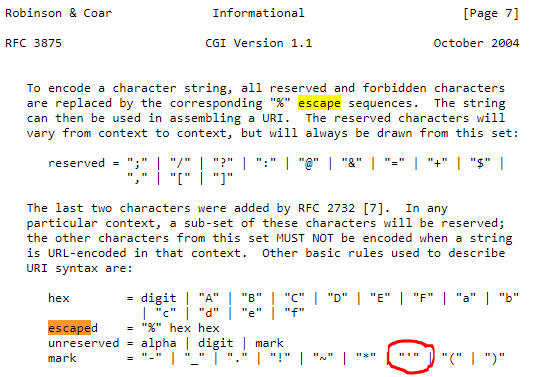
Let’s improve the escape function, that will escape single and double quotes too. As per Google recommendation, let’s add this function to gtl.py : _EscapeTextToHtml()
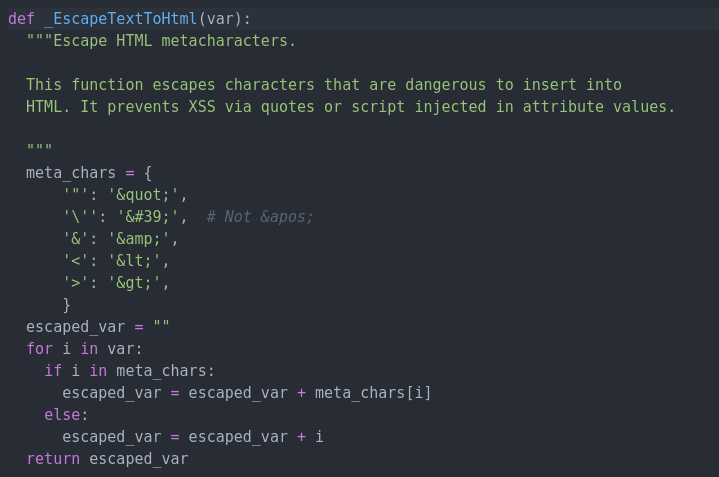
The single quote escape is this line : ‘\”: ‘'’. You can find some further explanations in this article : https://bit.ly/3j2tPjk
Let’s replace cgi.escape by _EscapeTextToHtml()
This is, in my case, efficiently blocking the script (my browser : Firefox in Kali Linux)
The rest of the questions are applicable for those of you still running a deprecated version of Internet Explorer, which had some flaws in dealing with CSS dynamic properties . Please refer to the explanations provided by Google, as I’m not going to perform this part of the Challenge
Stored XSS via AJAX
AJAX stands for Asynchronous JavaScript And XML. AJAX allows web pages to be updated asynchronously by exchanging data with a web server behind the scenes. This means that it is possible to update parts of a web page, without reloading the whole page
AJAX is not a programming language. It just uses a combination of:
- A browser built-in XMLHttpRequest object (to request data from a web server)
- JavaScript and HTML DOM (to display or use the data)
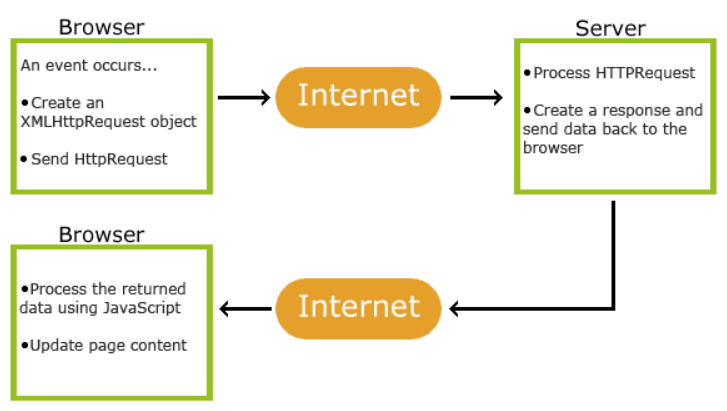
AJAX is quite a misleading name. AJAX applications might use XML to transport data, but it is equally common to transport data as plain text or JSON text
Here below an introduction video with some code examples
Gruyere uses AJAX principles to implement refresh on the home and snippets page
In a real application, refresh would probably happen automatically, but in Gruyere it is made manual. So, the user can be in complete control
When clicking the refresh link, Gruyere fetches feed.gtl which contains refresh data for the current page and then the client-side script uses the browser DOM API (Document Object Model) to insert the new snippets into the page. Here is an introduction video about the DOM, in case of need
Since AJAX runs code on the client side, this script is visible to attackers who do not have access to the source code
Let’s start the Challenge. We are invited to start a curl request on the feed.gtl page
What is curl ? It’s a command-line tool for transferring data specified with URL syntax. Find out how to use curl by reading the curl.1 man page or the MANUAL document. Find out how to install curl by reading the INSTALL document.
libcurl is the library curl is using to do its job. It is readily available to be used by your software. Read the libcurl.3 man page to learn how!
The most important part in the code is this one
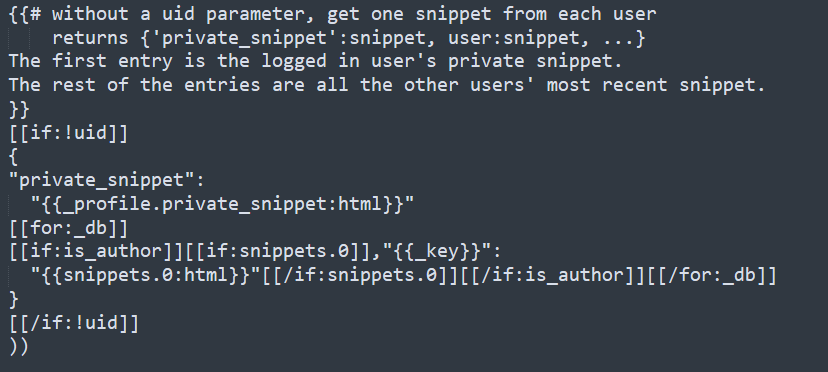
Here is the output of the curl request on the feed.gtl. The result is consistent with the above code
We see that the corresponding code has been inserted on the client side

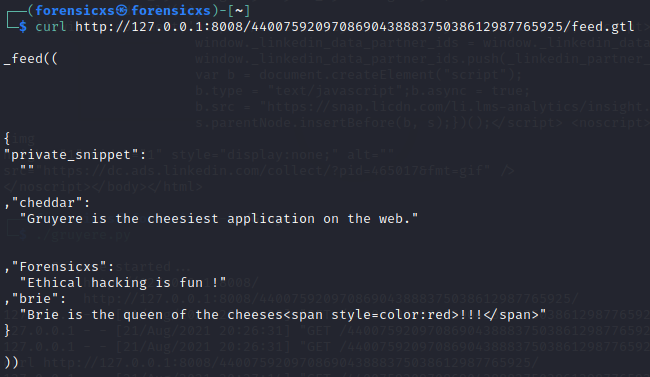
Now let’s input the code injection suggested by Google

The JSON output of the curl command reads like this. The code is injected
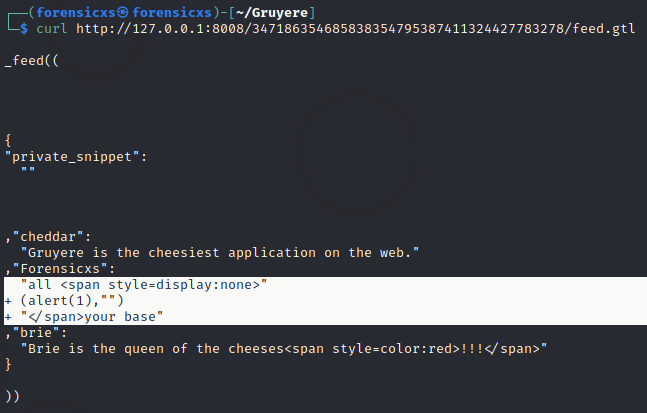
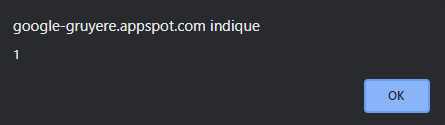
Now let’s click on the refresh button. There is a pop-up window with the “1” prompt. The snippet reads “all your base” (that means that our script is “invisible“), the rest of the script enables the pop-up window

That’s an evidence of a stored XSS via AJAX. The flaws are both on server side and client side
Server side :
The code below does not include any sanitizer (snippet:html or snippets.0:html)
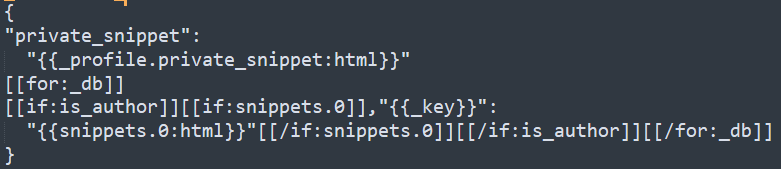
As Google says, the text is going to be inserted into the innerHTML of a DOM node so the HTML does have to be sanitized. However, that sanitized text is then going to be inserted into JavaScript and therefore single and double quotes have to be escaped too
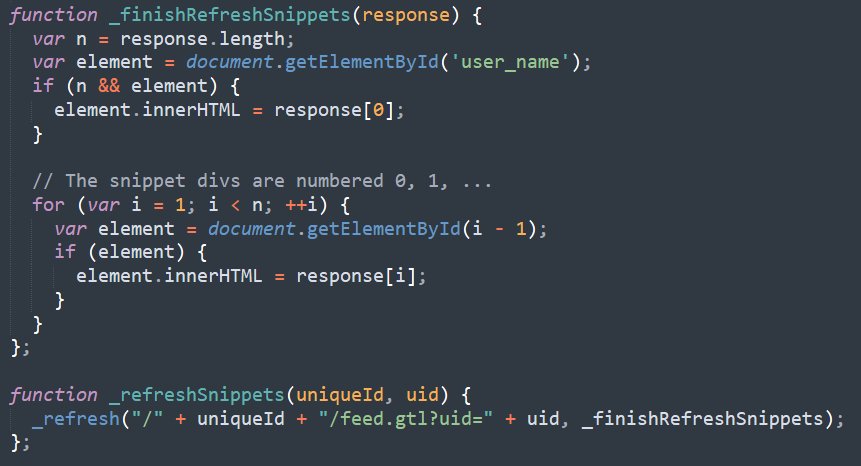
Client side :
A common use of JSON is to exchange data to/from a web server. When receiving data from a web server, the data is always a string. To become a JavaScript object, we have to parse the data
Gruyere converts the JSON by using JavaScript‘s eval() function : https://bit.ly/3gn4H54
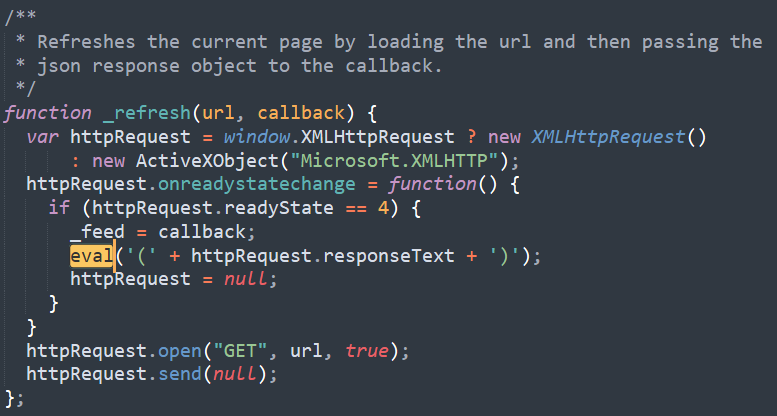
The eval() function evaluates or executes an argument. If the argument is an expression, eval() evaluates the expression. If the argument is one or more Javascript statements, eval() executes the statements
In modern programming eval is used very sparingly. It’s often said that “eval is evil”
The reason is simple : some time ago, JavaScript was a much weaker language, many things could only be done with eval. But that time is over

Right now, there’s almost no reason to use eval. If someone is using it, there’s a good chance they can replace it with a modern language construct or a JavaScript Module
It is recommended by Google to use the JSON.parse() function : https://bit.ly/2WccjjI
Reflected XSS via AJAX
This “reflected XSS via AJAX” is very close to what we did in the previous paragraph “Stored XSS via AJAX”
Google provides us the scripts to put to the test (the two lines will work in the same way)

The alert box is displayed as usual once we click the refresh button
Contrary to the Stored XSS, there is no code injection on the Server, it’s done directly in the Client
The flaw is in this section of the code
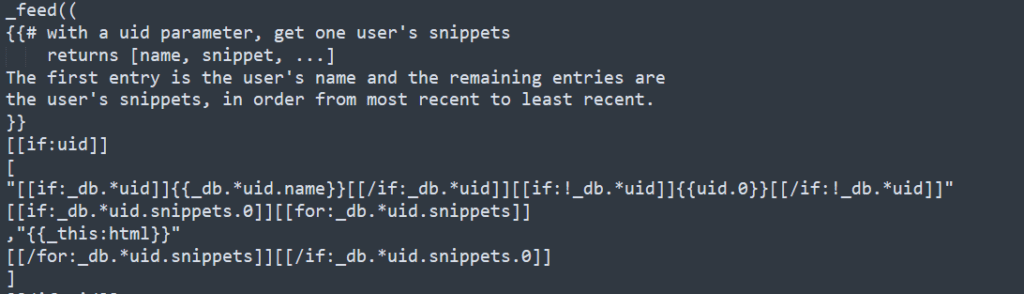
An HTML Sanitizer should be included to prevent such script to be executed
Python HTML Sanitizer
For a good security, it’s best to rely on a template language and apply a security technology designed for a template system. A self made Sanitizer will most likely not be a good solution
Therefore, let’s mention some well known HTML Sanitizers for Python and the template language Django, as Gruyere is based upon a similar technology with GTL
Bleach, is an excellent HTML Sanitizer, doing all the basic work of a Sanitizer. For correct operation inside a template language such as Django, you will need an extra layer provided by a Django HTML Sanitizer
- Bleach : https://github.com/mozilla/bleach

- Django HTML Sanitizer : https://github.com/ui/django-html_sanitizer

Client-State Manipulation
We should not trust any user data, the browser on the user machine actually sending this data back to our web server
Elevation of Privilege
Privilege escalation or elevation, can be defined as an attack that involves gaining illicit access of elevated rights, or privileges, beyond what is intended or entitled for a user
This attack can involve an external threat actor or an insider. Privilege escalation is a key stage of the cyberattack chain and typically involves the exploitation of a privilege escalation vulnerability, such as a system bug, misconfiguration, or inadequate access controls
In this Challenge, we are going to elevate our account to administrator, using a specially crafted user input, and taking advantage of some flaws in Gruyere code
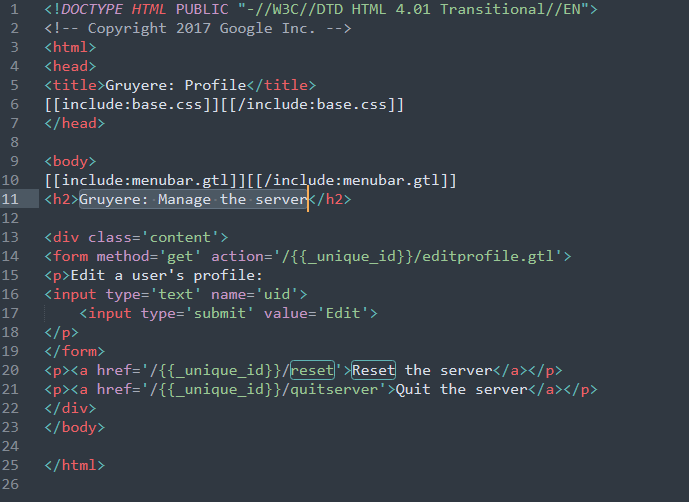
We notice some interesting code in the editprofile.gtl, showing the “saveprofile” process
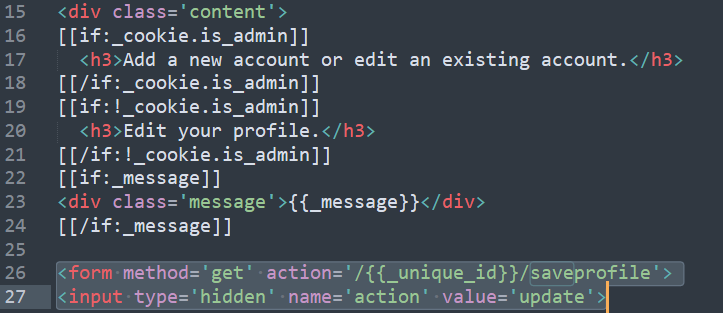
Therefore we can input the following code to our home URL :
/saveprofile?action=update&is_admin=True
We then need to log out and log in to update our session cookie. Then, a link “Manage this server” has appeared in our profile. We can input our name :
Our profile management page now has the admin and author buttons. That means our privileges have been elevated to administrator rights
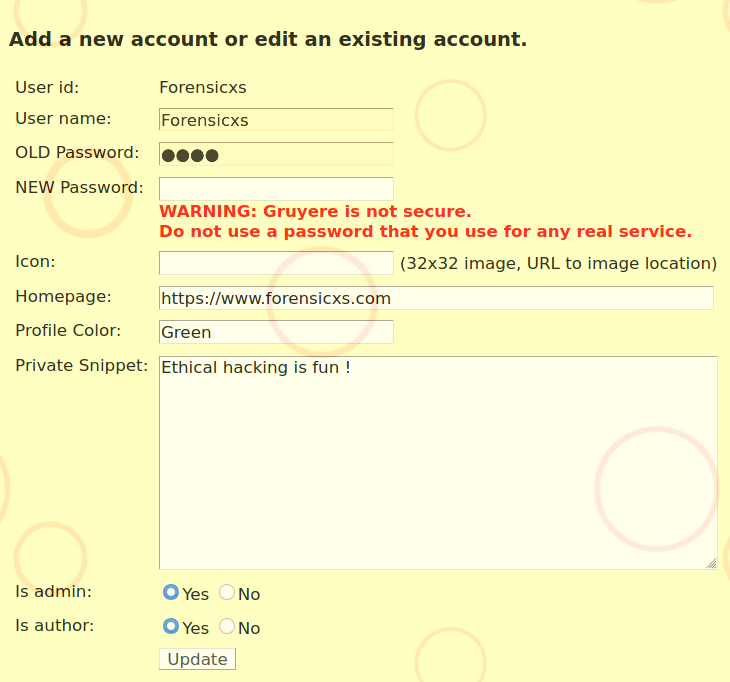
The flaw is that there are no validations of the above user query on the server side. A user ID without admin rights can place the request to become admin, which should not be possible
Here attached a complete walkthrough of this Challenge
Here below for further reading, some typical access control vulnerabilites and potential mitigations :

Cookie Manipulation
A stateless protocol is a communication protocol in which the receiver must not retain the session state from previous requests. The sender transfers relevant session state to the receiver in such a way that every request can be understood in isolation, that is without reference to session state from previous requests retained by the receiver
Examples of stateless protocols include the Internet Protocol (IP), which is the foundation for the Internet, and the Hypertext Transfer Protocol (HTTP), which is the foundation of the World Wide Web
Web server cannot automatically know that two requests are from the same user. For this reason, cookies were invented
When a web site includes a cookie in a HTTP response, the browser automatically sends the cookie back to the browser on the next request. Web sites can use the cookie to save session state
Cookies are usually numeric hashes plaintext variables used by your browser to store that information and communicate it to the server — allowing you to sign in without logging in, because you’ve already been authenticated by your cookie
If cookies authenticate an individual, then if someone else steals that cookie, they can impersonate the person it’s tied to — accessing their account, payment information, and other sensitive details without having to know their username or password
Gruyere uses cookies to remember the identity of the logged in user, in this format [hash|User name|admin|author]
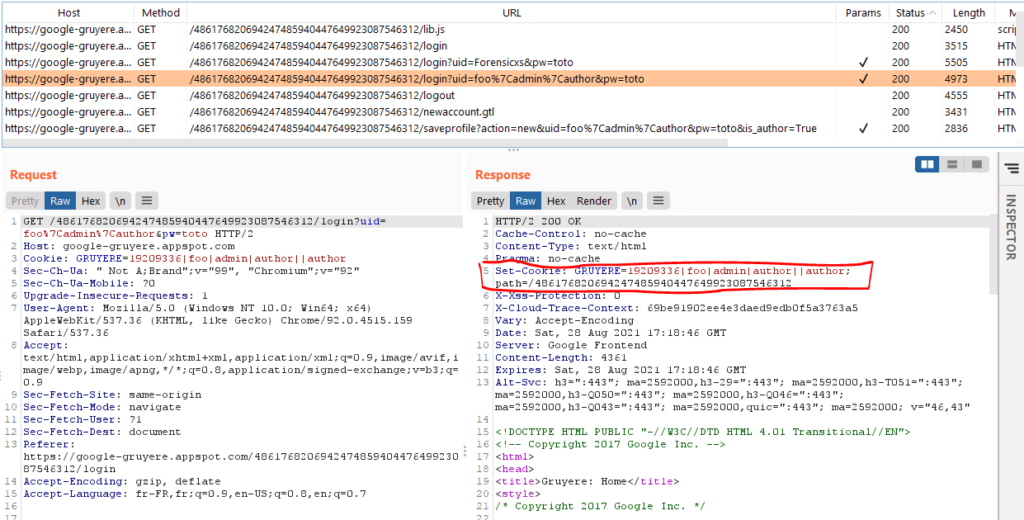
Here is my session cookie visible in Burp Suite :
Set-Cookie: GRUYERE=112960044|Forensicxs|admin|author; path=/486176820694247485940447649923087546312
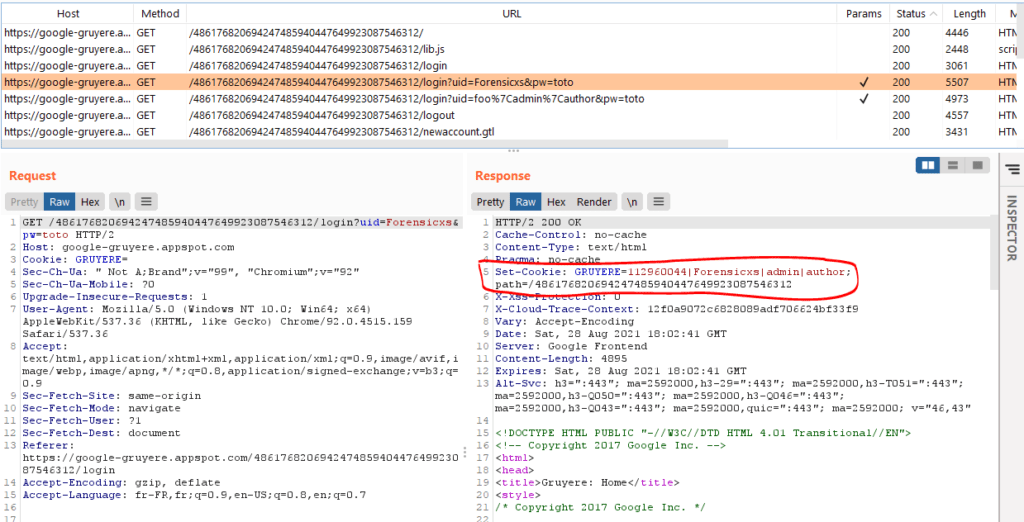
Now, let’s create a new account with the user name foo|admin|author and let’s see the result in Burp :
Set-Cookie: GRUYERE=19209336|foo|admin|author||author; path=/486176820694247485940447649923087546312
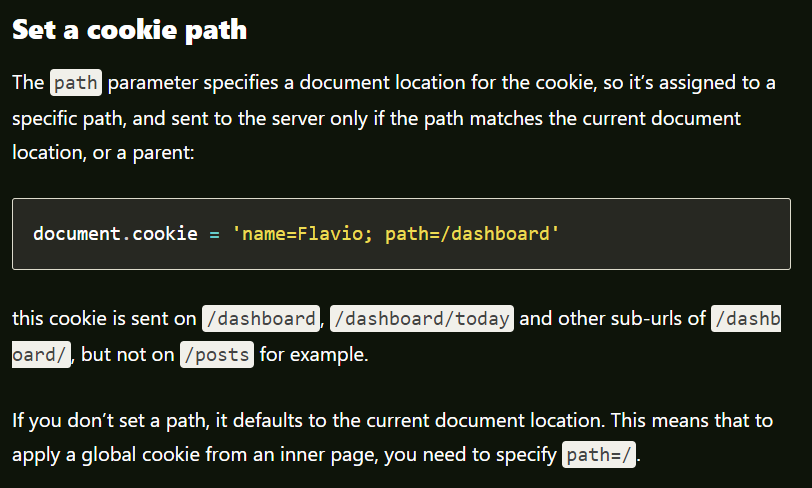
What is a cookie path, and how to define it ? Read below :
So, in our unique session ID, we have been able, under the same path, to trick Gruyere to issue a cookie that looks like the cookie of another user. We have also, as a side effect, been able to perform a privilege escalation as we gained admin rights. By inputing the string (foo|admin|author) into the username field we have successfully created an account which will return a cookie for someone with the username ‘foo’ and with admin rights
The code used to parse cookies on the server-side is tolerant to abnormal cookies — a cookie string with varying characters and lengths will still be read by the server. This means that an attacker doesn’t need to know how cookies are parsed on the server-side to pass a malicious cookie
Here are the security recommendations from Google :
- The server should escape the username when it constructs the cookie
- The server should reject a cookie if it doesn’t match the exact pattern it is expecting
We can see in the code below that only basic checks are included at the creation and afterwards
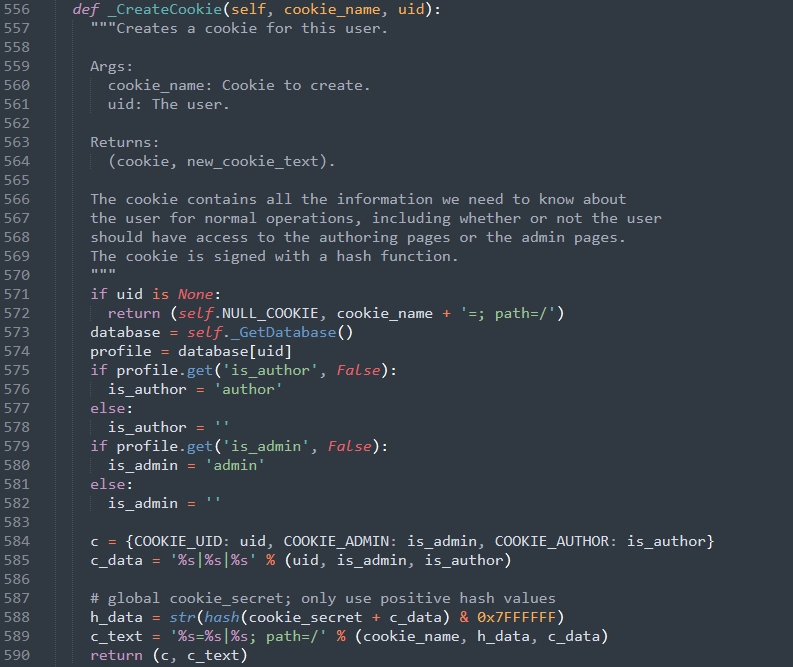
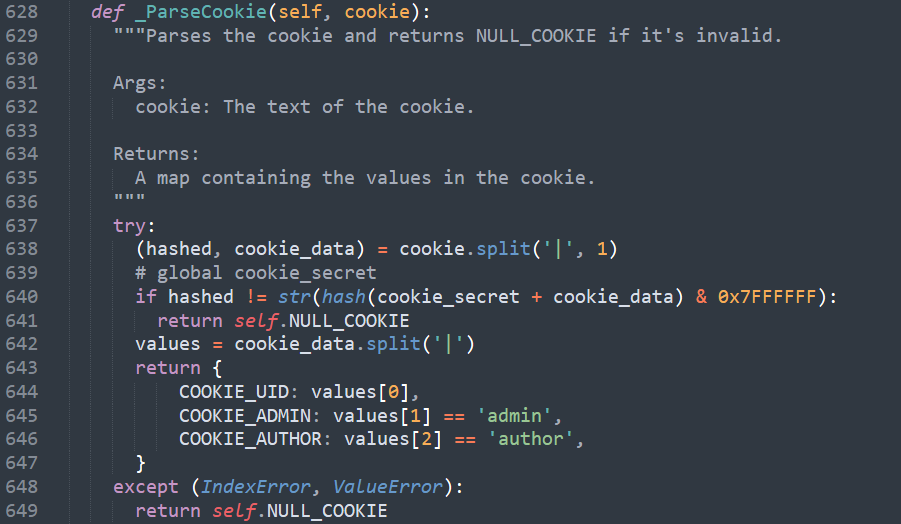
Here further reading about Cookie Security : https://bit.ly/3JlQMJu

Nowadays, Web Application Firewalls (WAF) are putting protections against cookie related attacks, such as this one : https://bit.ly/3jpaZD5
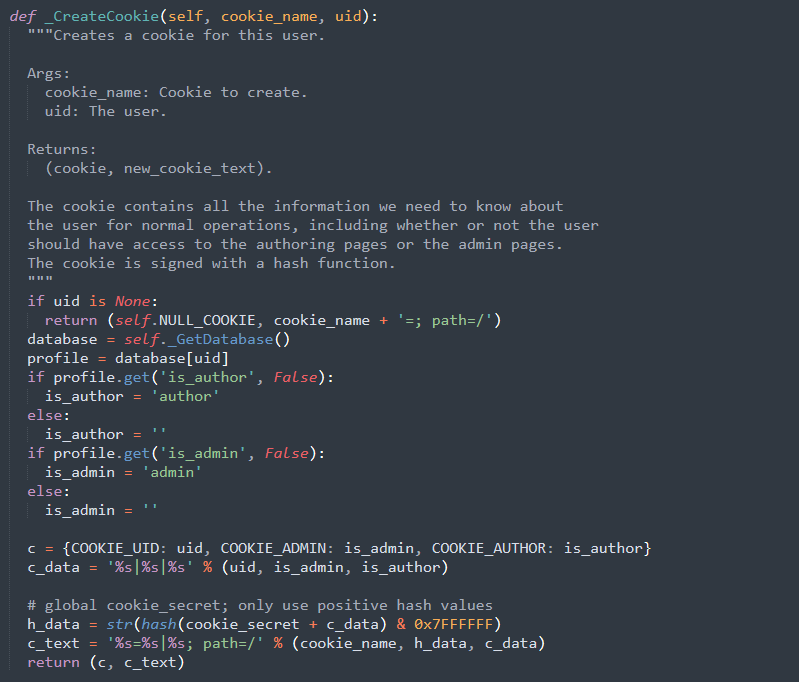
Now, let’s have a closer look to the cookie hash function :
h_data = str(hash(cookie_secret + c_data) & 0x7FFFFFF)
- cookie_secret : is a static string (which is just ” by default, that means an empty string is the cookie secret), used as initialization vector or salt
- c_data : is the username
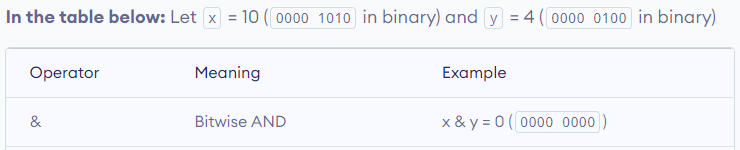
- & 0x7FFFFFF : AND operator with Hex 0x7FFFFFF
- str(hash()) : string hashing function
- h_data : hashed username
Python’s hash() is not fit for the purpose – or let’s say “insecure” in this context – because it’s possible to find cryptographic collisions. It is not a bug in Python, it’s just that it is not what it’s designed for in this use case
This hash() function is used in Python’s dictionaries hash tables, where you can’t “afford” a fully secure hash function, because it would slow down so much the calculations and the use of these dictionaries
Here a video explaining in detail these hash tables and collisions
Python does provide secure hash functions in the hashlib module : https://bit.ly/3gK3hlb. They are used each time a cryptographic secure application has to be implemented
Because of it’s lack of cookie protection, Gruyere is also prone to replay attacks : https://bit.ly/2WzSdjQ
Cross-Site Request Forgery (XSRF/CSRF)
Cross-site request forgery (also known as XSRF/CSRF) is a web security vulnerability that allows an attacker to induce users to perform actions that they do not intend to perform. It allows an attacker to partly circumvent the same origin policy, which is designed to prevent different websites from interfering with each other
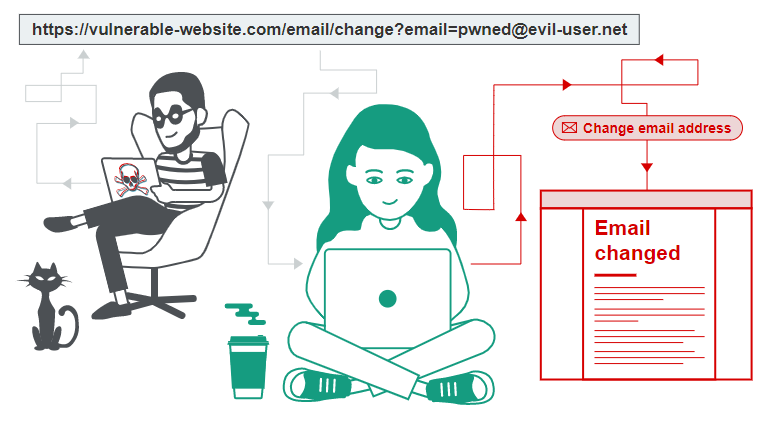
Let’s look at the URL used to delete a snippet. For this, let’s actually delete our snippet and check the result in Burp Suite
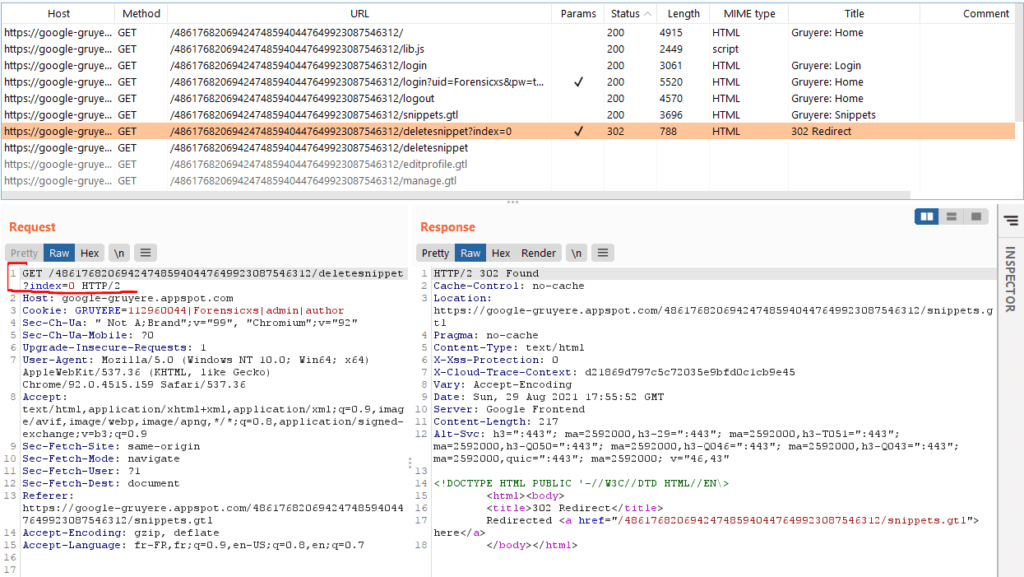
We find the GET request : /deletesnippet?index=0
So now we can easily simulate a CSRF attack. We can put the complete URL https://google-gruyere.appspot.com/486176820694247485940447649923087546312/ deletesnippet?index=0 in our Gruyere icon, using the Edit Profile feature
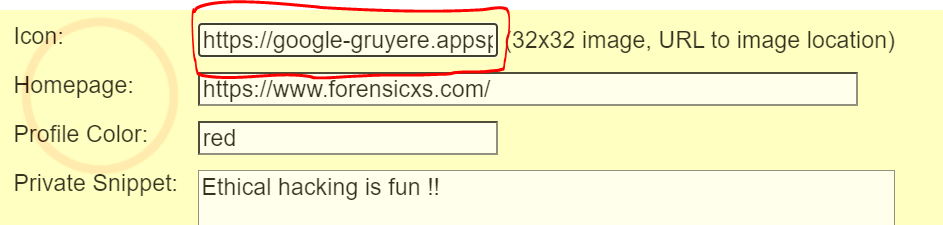
You can check by yourself, that each time you will put a snippet in your page, and refresh the home page, the snippet will be automatically deleted

To trigger the attack, we could imagine luring a victim to browse a page where this URL is embedded
Now, let’s look into the code. In the Edit Profile form, the code is accepting whatever text we are typing without any check

The Edit Profile code uses the GET Method in the user input forms

When we include deletesnippet?index=0 in the icon form, and after refresh, this triggers an action on the server with the function def _DoDeletesnippet
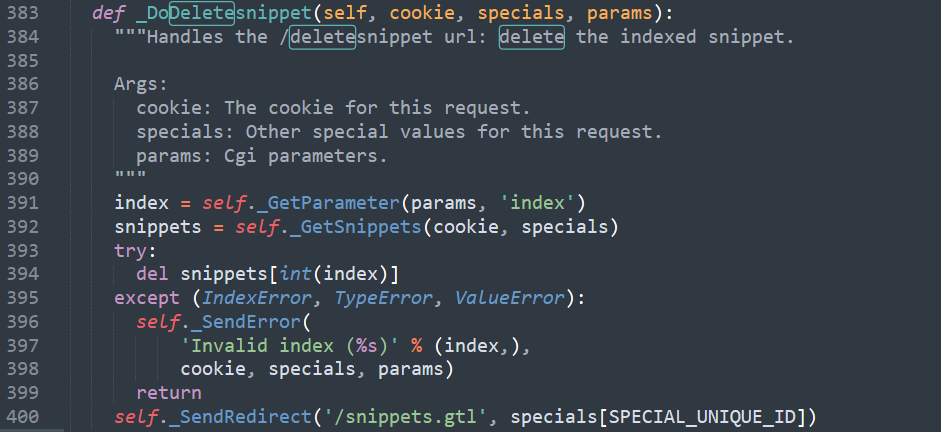
The deletion of our snippet is then handled via this code
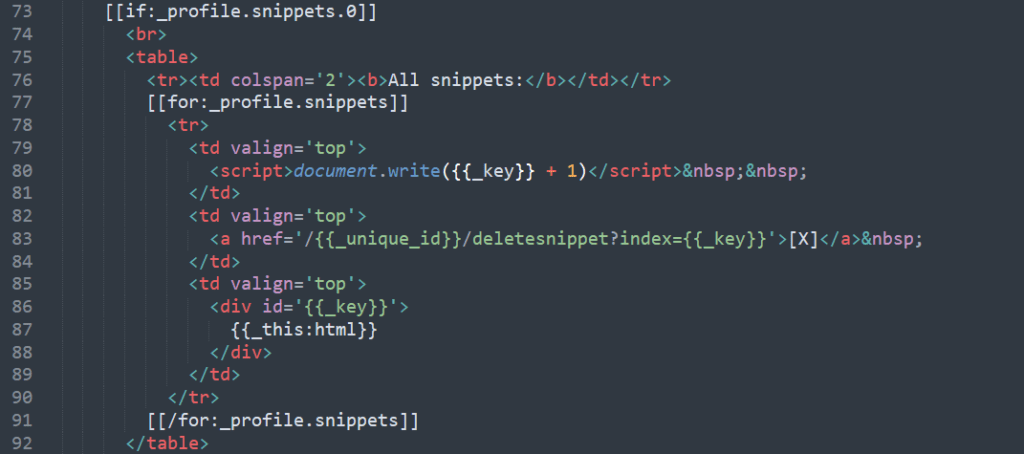
We find that Grueyere has a systematic flaw, which is the use of GET request instead of POST request, for sending and updating sensitive data
GET is used for viewing something, without changing it, while POST is used for changing something. For example, a search page should use GET to get data, while a form that changes your password should use POST. Essentially GET is used to retrieve remote data, and POST is used to insert/update remote data
GET request retrieves a representation of the specified resource and include all required data in the URL. For example :
https://www.example.com/login.php?user=myuser&pass=mypass
POST request is for writing and submit data to be processed (for example from an HTML form) to the identified resource. This may result in the creation of a new resource or the updates of existing resources or both. It may have side effects using the same request several times because this will likely result in multiple writes. Browsers typically give you warnings about this. POST is not fully secure, the data is included in the body of the request instead of the URL but it is still possible to view/edit
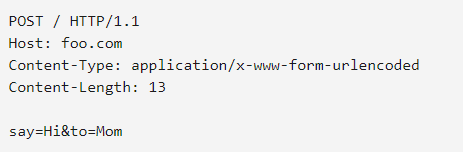
Here is a quick summary :

A first action would be to change the GET to a POST request, as the GET method is not appropriate in this context. But, this will definitely not be sufficient
Here are a set of countermeasures to apply :
- Enumerate the form values, evaluate that no extraneous fields show up, and sanitize and filter on expected values
- CSRF tokens help against arbitrary form submission bots
We have already seen sanitizing in the previous chapters. Let’s go deeper in the CSRF tokens
To avoid a CSRF attack, a potential solution is to embed additional authentication data into the HTTP request, so the web application will be able to detect any unauthorized requests crafted by an attacker and placed into a form
CSRF tokens are typically random numbers that are stored in a cookie or on a server. What will happen is the server will compare the token attached to the incoming requests with the value stored in the cookie or the server. If the values are identical, the server will approve the request. Similarly, it will reject the request if the token is missing or is incorrect
Google proposes to pass an action_token in all HTML requests, and use a hash of the value of the user’s cookie appended to a current timestamp (the timestamp in the hash will ensure that old tokens can be expired, which mitigates the risk if it leaks). The POST request will mitigate the risk to pass action_token as a URL parameter and let it leak
Here is the proposed code :

With such a token, an attacker would also need to guess the token to successfully trick a victim into sending a forged request
For an anti-CSRF mechanism to be effective, it needs to be cryptographically secure. The token cannot be easily guessed, so it cannot be generated based on a predictable pattern
It is recommended to use anti-CSRF options in popular frameworks such as AngularJS (https://bit.ly/3yMmGYO) and refrain from creating own mechanisms
As a last word, you can find here a good summary how to protect your forms from malicious inputs : https://bit.ly/3kRgav7
Cross Site Script Inclusion (XSSI)
XSSI is a client-side attack similar to Cross Site Request Forgery (CSRF) but has a different purpose. Where CSRF uses the authenticated user context to execute certain state-changing actions inside a victim’s page (reset password, etc.), XSSI instead uses JavaScript on the client side to leak sensitive data from authenticated sessions

Let’s follow the example provided by Google. Here is my private snippet on my home page. This is the “sensitive information” that we are going to leak

We can see that the /feed.gtl discloses informations about our private snippet, as already seen earlier in this article

The following code will take over my private snippet content and display it in an alert text box, using Javascript. The HTTP adress points to my local server 127.0.0.1:8008 and my private session, as I’m running Gruyere locally for this XSSI exploit
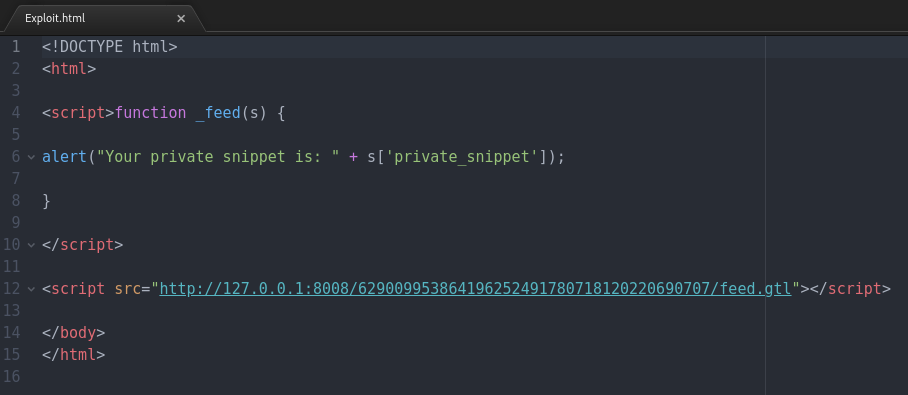
My Exploit.html is located in my root Gruyere directory (resources)
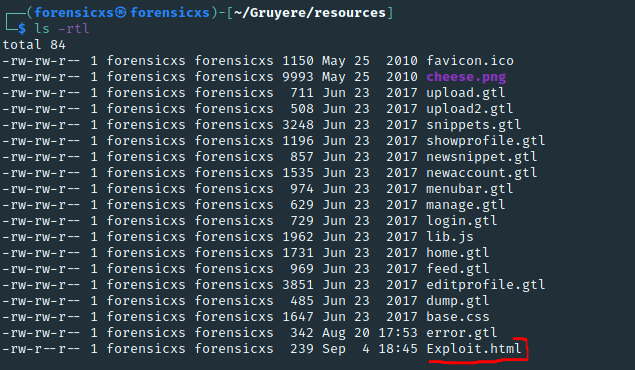
The content of my private snippet is shown in the alert box. That’s our sensitive data leak
Here below some potential countermeasures :
- Use a CSRF token (as discussed earlier), to make sure that JSON results containing confidential data are only returned to your own pages
- JSON response pages should only support POST requests, which prevents the script from being loaded via a script tag
- Make sure that the script is not executable (with sanitizing). The standard way of doing this is to append some non-executable prefix to it. A script running in the same domain can read the contents of the response and strip out the prefix, but scripts running in other domains can’t
Here are more XSSI examples on the OWASP site : https://bit.ly/3kTbBAu
You can also check this video from blackhat Europe that provides more explanations
Path Trasversal
Information disclosure via path travsersal
A common attacker technique is Path Traversal to access files outside of the intended directory : https://bit.ly/3BKWuzF
An attacker may be able to read an unintended file, resulting in information disclosure of sensitive data. Or, an attacker may be able to write to an unintended file, resulting in unauthorized modification of sensitive data or compromising the server’s security
Modern web applications and web servers usually contain quite a bit of information in addition to the standard HTML and CSS, including scripts, images, templates, and configuration files. A web server typically restricts the user from accessing anything higher than the root directory, or web document root, on the server’s file system
A secret is an object that contains a small amount of sensitive data such as a password, a token, or a key. Using a secret means that you don’t need to include confidential data in your application code
A Path Trasversal attack will target stored secrets, among other things
Let’s start Burp Suite and check my Gruyere session site map. For this the easiest is to use the Burp browser (inside the App), as it will manage the proxy for you, and intercept the HTTP requests. Here is the result :
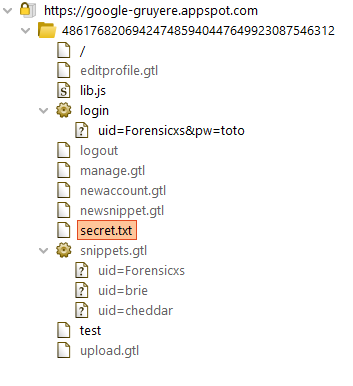
We can see that there is a secret.txt file, that’s our target. Let’s see if Gruyere is sensitive to Path Trasversal attacks
Let’s try with the upload.gtl module. Normally we should not be able to access the code…but we can !
Here is the result when we enter /upload.gtl (expected behaviour)
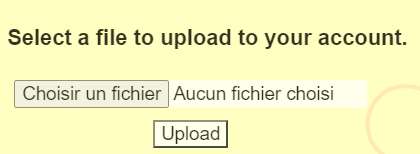
Let’s go down a level and type in /upload.gtl/test, the result is as follows, as this file “test” does not exist in this hierarchy

Now, let’s move one level back with /upload/test/../, and here is the result. This confirms that Gruyere is vulnerable to Path Trasversal
Now let’s find the content of the secret.txt file. I’m on Chrome, so this may not work exactly the same way on your browser. Chrome does not accept the plain ../ command, but we can easily trick the browser with the hexadecimal translation of the slash / into 0x2f or %2f

Let’s type in /secret.txt. This returns the error message as above
Now, let’s step up with the path /..%2fsecret.txt. We find the content of the secret.txt file is Cookie!

An additional note : here is a usefull reminder about commands to move in a file system

Data tampering via path trasversal
Now that we have found that Gruyere is vulnerable to path trasversal, we can easily craft a data tampering attack, by changing the content of the secret.txt file. I have chosen “Path Trasversal” in my file. First, we must upload the file in our session
Now, let’s repeat the actions from the previous paragraph, to launch the path trasversal attack :
/secret.txt
/..%2fsecret.txt
We find that the secret.txt file has been replaced by the new one

Let’s conclude this chapter by a few countermeasures
- don’t store sensitive files on your web server. The only files that should be in your document root folder are those that are needed for the site to function properly
- make sure you’re running the latest versions of your web server
- sanitize any user input. Remove everything but the known good data and filter meta characters from the user input. This will ensure that attackers cannot use commands that try to escape the root directory or violate other access privileges
- remove “..” and “../” from any input that is used in a file context
- ensure that your web server is properly configured to allow public access to only those directories that are needed for the site to function
Denial of Service
Here we will try some tricks to prevent the Gruyere server from servicing requests, by taking advantage of some server code bugs
DoS – Quit the Server
As we are logged in as admin (from previous privilege escalation achieved in this article), let’s check how to request a server quit command. This is to be found in the “Manage this server” section

We find in the address bar that it is handled by the manage.gtl
Now let’s create a new account without admin rights. We notice that it is still easy to ask the Gruyere server to quit. Just type in /quitserver

Let’s check how we can achieve this while we are not logged in as admin. The key question is how Gruyere is preventing this query to achieve its goal
In fact, Gruyere does include some so called “Protected URLs” in the server code

What is this ? A website is, in general, available to the public. But there could be a need to have a seperate area that is NOT available to the public. That’s where the Protected URL comes in. It allows to make a certain directory of a site not available to the public, and instead, prompt the visitor for a username and password
Let’s solve the bug by adding /quitserver to the Protected URLs
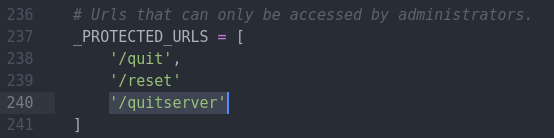
Because of the below code, Gruyere will send back an “invalid request” message when you try to type in a protected URL

DoS – Overloading the Server
We need to find a way to overload the server when a request is processed. For this, we have seen that Gruyere is vulnerable to Path Trasversal attacks
To overload the server, one idea is to use a resource that will put Gruyere in a kind of “infinite loop”, with a request repeating without end, whatever we click in our session
We see that the menubar.gtl file is in every page we navigate, so this makes a good candidate for this attack

We can create a file named menubar.gtl, that will be replacing the existing one, with the following content
[[include:menubar.gtl]]DoS[[/include:menubar.gtl]]
We can upload and replace the existing menubar.gtl, using a Path Trasversal attack. We can create a new user called ../resources, then upload the file using this user profile. This will implement the attack on the resources directory and copy-paste the new file in there
Here is the result, this loop repeats itself, each time we perform a refresh or navigate in the site

We need to use the “reset button” to stop this loop
https://google-gruyere.appspot.com/resetbutton/session ID
The potential fix has been described earlier in the Path Trasversal section
Code Execution
Google tells us to use two previous exploits to execute code. We will therefore use Path Trasversal and Denial of Service
The general idea here is to take advantage of these vulnerabilities, to attack the Gruyere infrastructure. How to do that ? The GTL template language is a target of choice, as GTL is shaping the entire Gruyere web site. Modifying the GTL language can permanently alter the site and put it down. We will leverage this attack using the Path Trasversal and Denial of Service
We are therefore going to replace the “gtl.py” file with our own, and “rewrite” the site’s infrastructure and thus “own” the application
The content of the GTL file can be anything. I just wrote in an empty file “Code Execution Challange” and named it gtl.py
Then I prepared the Path Trasversal attack by creating the user .., and uploading my file in this profile

Then, I restart the server by typing /quitserver. Gruyer puts the following message : the server has been 0wnd! I have found a way to attack the infrastructure and “own” the server, by replacing the gtl.py file
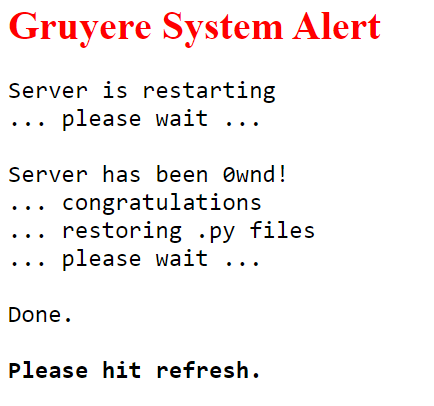
There are several flaws in Gruyer code :
- gruyere allows users to upload a file with the .py extension (Python file). This should be blocked by a proper sanitization, as seen previously
- gruyere should be modified for path trasversal flaws, as seen above
- gruyere has permission to both read and write files in the gruyere directory. This should not be the case, and gruyere should run minimal privileges (https://bit.ly/3typbgB)
- more generally and for a real world site, your infrastructure should be updated (such as libraries imported by your code), to avoid typical vulnerabilities
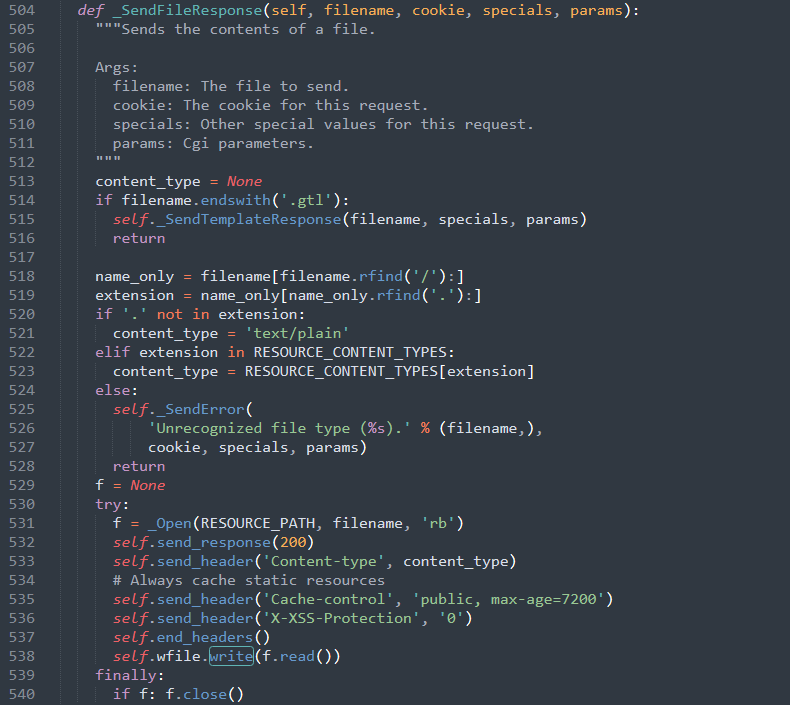
In the Gruyere code, the following code section should be modified to restrict the possibilities to write file
Configuration Vulnerabilities
We are going to try leaking datas stored in the Gruyere database. This is a cool challenge as database exposures are such a big thing nowadays
Information disclosure #1
Looking into the file system of Gruyere, we notice an interesting and potentially sensitive file which is dump.gtl
Here is the code
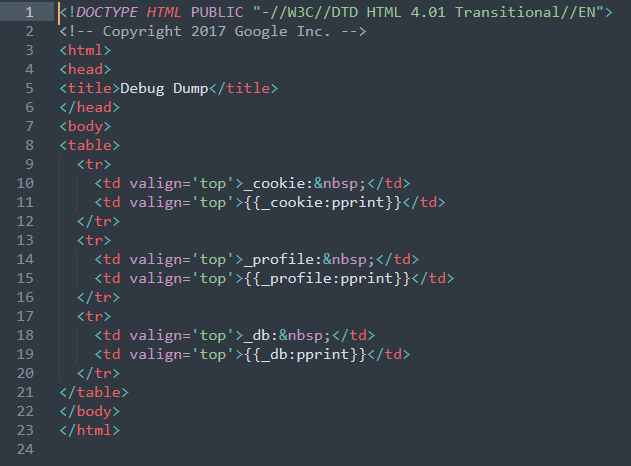
It really looks like a database dump program. What is this ?
Usually, a database dump contains a record of the table structure and/or the data from a database, and in real life, is usually in the form of a list of SQL statements
A database dump is most often used for backing up a database so that its contents can be restored in the event of data loss. The database program will allow to extract the database data for backup. It can also be used in situations where you need to debug the server
To access the dump, just type this address in your session : /dump.gtl
Here is the content of the dump, consistent with the above code
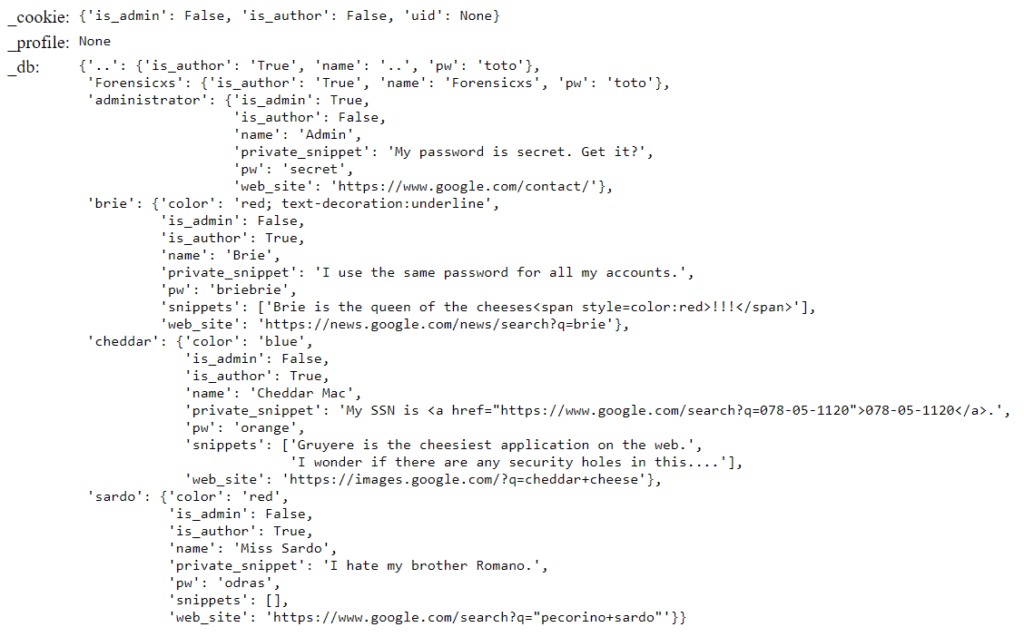
We can see user names and passwords in clear text
There are obviously major flaws here :
- first of all, this file should not be stored here
- passwords are not hashed or encrypted, but stored in clear text
- the dump program should be strictly restricted to admin rights
- the dump files should be stored in a specific location with a specific access mechanism (IP, port, authentication)
Here are the OWASP recommendations for database security : https://bit.ly/2XtsOsg. Obviously Gruyere did not implement any of these recommendations
To build further awareness of potential exploitation of debuggers in real life, I suggest to check this link : https://bit.ly/2VNQxCO
Are such situations common in real life ?
Unfortunately, Gruyere is quite representative of what you can find on websites exposed to the Internet. We all know that there are thousands of databases which are ill-configured and exposed to attackers
You can have a first look by typing this query in Google : intitle:”index of/” “*.sql”
This will just search for SQL databases in websites root directory, and reveal many exposed databases (some being quite critical from a GDPR point of view)
Information disclosure #2
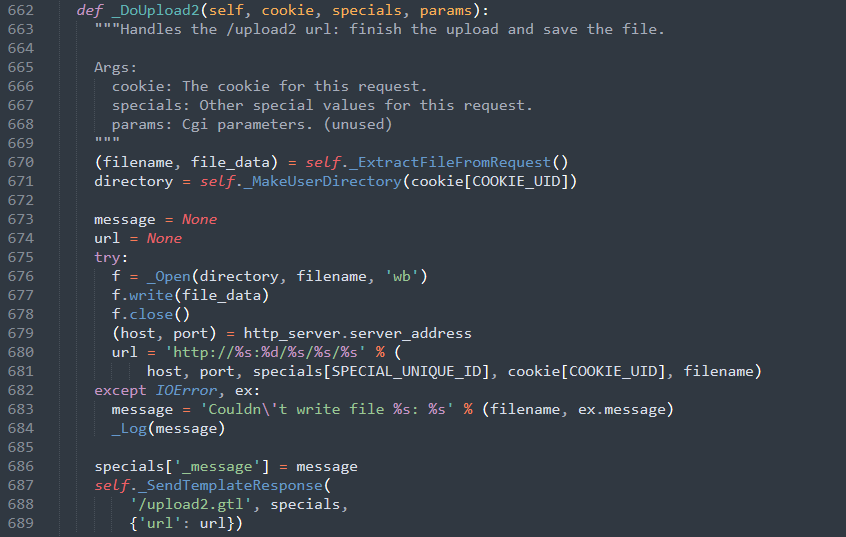
Unfortunately, deleting the dump.gtl file will not secure Gruyere. One big issue, as we know, is that we can easily upload any kind of file we want. So, we can upload another dump script and leak the data
There should be protections included in the code (preventing some file formats such as templates, scripts,…). The following code on the server side permits unrestricted file uploads
Here is a valuable checklist focused on file upload vulnerabilities : https://bit.ly/3Crw0E, and also a good video about file upload vulnerability, providing a quite thorough review of the topic
Information disclosure #3
The target here is to continue leaking the Gruyere database, not using a dump function or upload vulnerability, but relying on the Gruyer code weaknesses
We can try using some functions existing in Python, such as pprint – data pretty printer, to display the database content, and inject this directly into the “new snippet” window
The pprint module provides a capability to “pretty-print” Python data structures. The formatted representation keeps objects on a single line if it can, and breaks them onto multiple lines if they don’t fit within the allowed width
In a template language such as Django, variables look like this : {{ variable }}
When the template engine encounters a variable, it evaluates that variable and replaces it with the result
Reading into the GTL language, we see some explanatations : “db” stands for the database variable in the GTL language and can be used as a special value
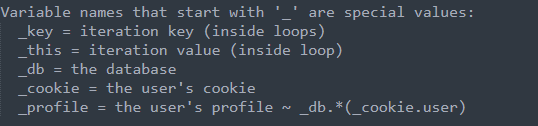
So, we can input this variable in the “new snippet” window, as the GTL language will interpret the result
{{_db:pprint}}
Here is our database directly on the “my snippet” page

There is one flaw in the way the template code parses the variable values
ExpandTemplate calls _ExpandBlocks followed by _ExpandVariables
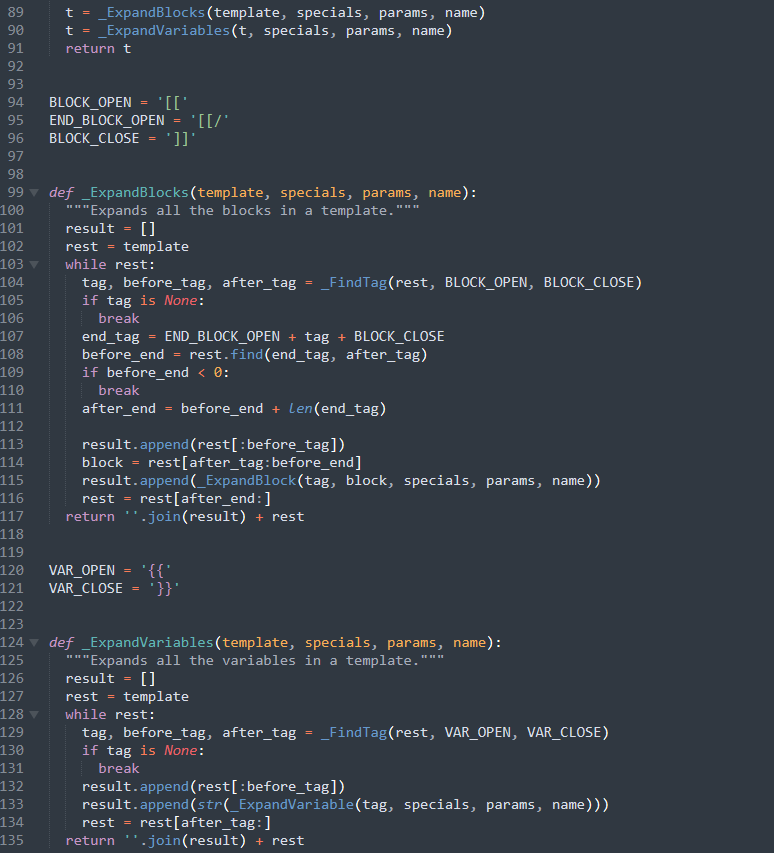
_ExpandBlock calls ExpandTemplate on nested blocks. So if a variable is expanded inside a nested block and contains something that looks like a variable template, it will get expanded a second time
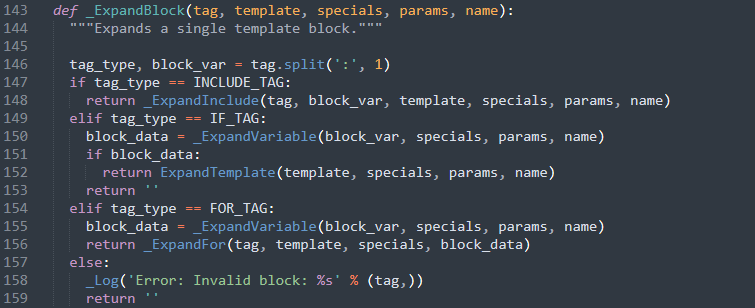
In addition to this design flaw, the template language should not allow arbitrary database access and should narrow down the queries possibilities
AJAX vulnerabilities
Before starting these last two challenges, let’s remind what we have seen earlier
Gruyere uses AJAX principles to implement refresh on the home and snippets page
When clicking the refresh link, Gruyere fetches feed.gtl which contains refresh data for the current page and then the client-side script uses the browser DOM API (Document Object Model) to insert the new snippets into the page
Since AJAX runs code on the client side, this script is visible to attackers who do not have access to the source code. We can see the code using Burp Suite
DoS via AJAX
First of all, let’s sign in using my Gruyere account “Forensicxs”
We can see the snippets. Clicking on “refresh”, we see the response corresponding to the snippets content
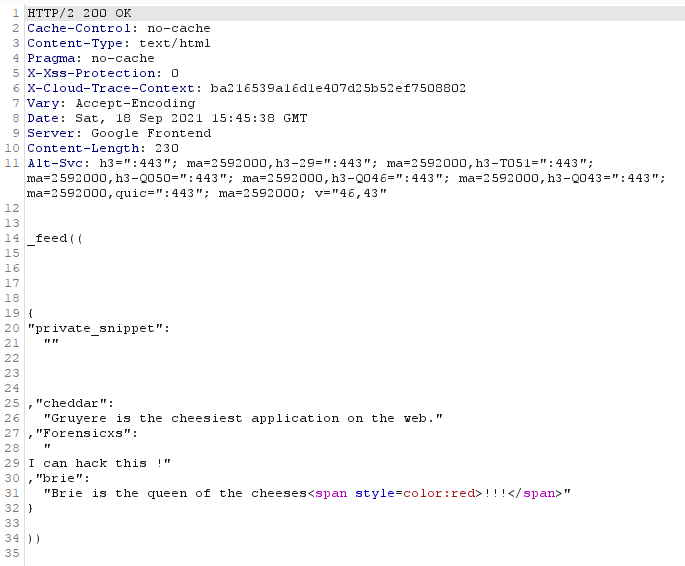
Then, let’s create a user “private_snippet“, and create several snippets

Here is the response. The snippets of the other users have been deleted
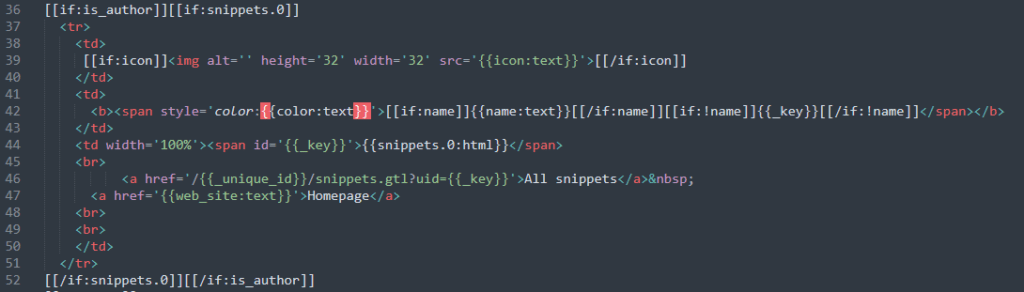
The flaw here is the structure of the response. We see the construction here

And also in the lib.js
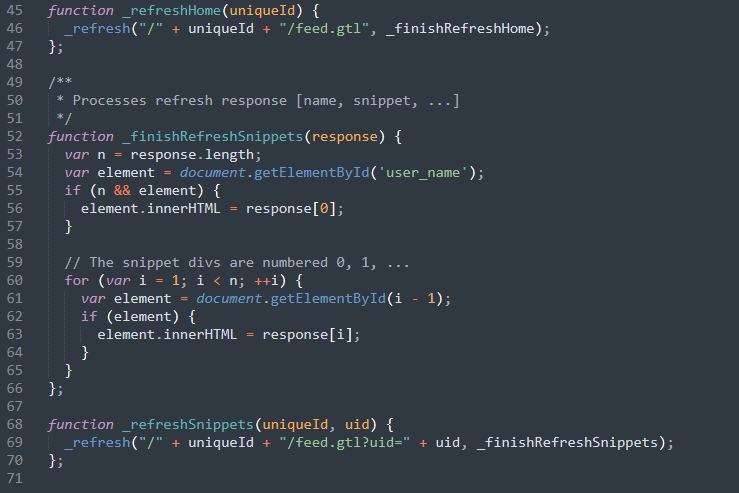
This manipulation of the Document Object Model, by injecting code and pushing a data “offset”, is somehow similar to a buffer overflow
Google says that the structure of the response should be as follows, to avoid this “offset” of the user snippets by the attacker snippets :
[<private_snippet>, {<user> : <snippet>,…}]
Phishing via AJAX
The target here is to inject in the page some links to a phishing site
I created a user called “Phishing”, and I created a snippet with the following text
<a href='https://www.forensicxs.com'>Sign in</a> | <a href='https://www.forensicxs.com'>Sign up</a>
Here is the result

So now, we have on the page additional links to sign in/sign up. A user could be tricked to click on such links and trigger a phishing attack, by forwarding the user to a specially crafted page looking like the Gruyere page, and including some malicious code to take control of the user session
We have seen in these two challenges, that the DOM should be better protected against potential manipulations, for example, by applying a prefix to user values like id="user_"
Conclusion
We have seen most of the major web hacking techniques in this article. For learning, Google Gruyere is really a very good platform, as it combines the client side application, but also the server code, together with a well documented walkthrough
I hope this article provides you further help for a good understanding. In any case, thanks to the Google team for providing this excellent learning platform